

Comment nous avons préparé Azure à un pic de trafic massif après une diffusion sur M6 et TF1
Introduction
En tant qu’architecte technique d’une application mobile et web pour un client, avec l’équipe de développement, nous avons dû nous préparer à recevoir une forte affluence sur un temps très court sur l’application et le site web.
Cette application permet aux conducteurs routiers de trouver des points d'intérêt sur une carte. Ils peuvent notamment rechercher des restaurants routiers, des parkings, des stations-service et bien d’autres endroits répondant à leurs besoins, comme la présence de douches ou de machines à laver. L’application intègre également un GPS Poids-Lourd en option.
Le samedi et le dimanche sont habituellement des journées calmes pour les serveurs de notre application. Les utilisateurs consultent principalement l’application en fin d’après-midi la semaine afin de préparer leurs arrêts. Nous observons donc généralement une montée progressive du trafic tout au long de la journée avec un pic entre 17h et 18h.
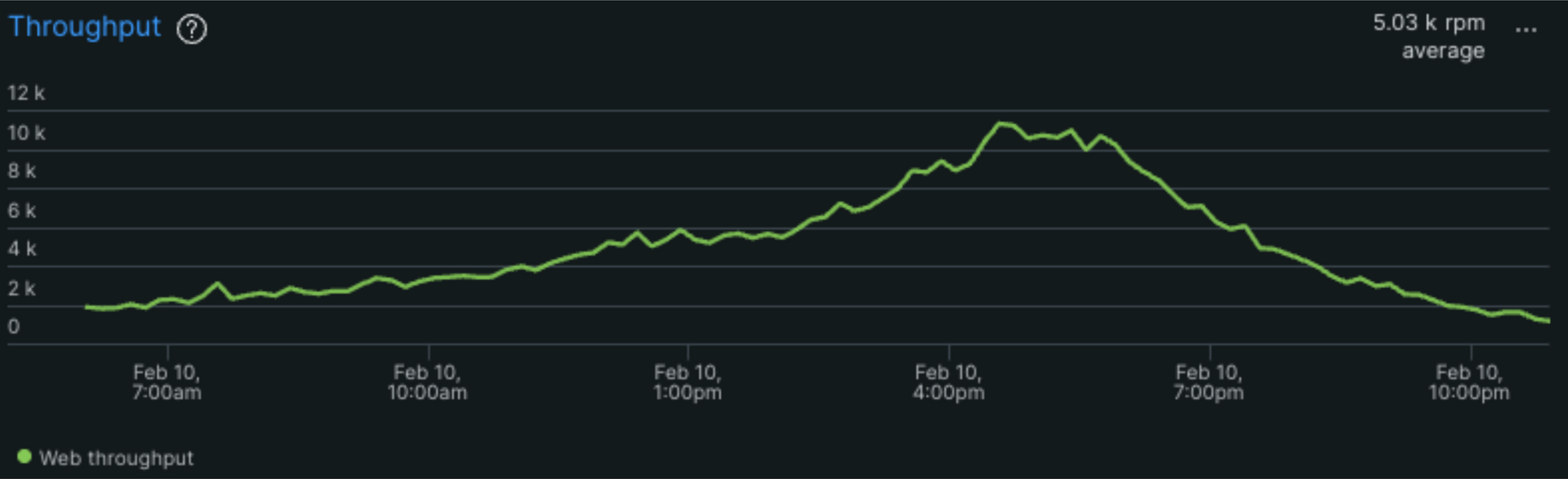
Notre backend Azure App Service a donc habituellement le temps de monter de nouvelles instances automatiquement sans downtime grâce au scale out automatique.
Mais un samedi, la routine a laissé place à l'effervescence : un reportage d’une grande chaîne télévisée a mis l'application sous les projecteurs, déclenchant un afflux soudain d'utilisateurs dans un laps de temps trop court pour être absorbé par l’infrastructure habituelle.
Le principal risque n’était pas uniquement technique. L’application est très connue auprès des conducteurs routiers et une indisponibilité aurait rapidement dégradé son image de marque. De plus, lorsqu’une application ne répond plus, les mauvais commentaires arrivent très vite sur les stores Apple et Google.
Commence alors une journée hors norme pour notre équipe. Grâce à une stratégie préventive mêlant scale up et scale out, nous avons pu absorber cette montée en charge sans interruption de service.
Chronologie d'une montée en charge éclair et trafic associé
L'émission a offert à l’application trois moments de visibilité stratégiques, chacun provoquant une réaction immédiate sur les courbes de trafic.
| Heure | Type d'apparition | Impact observé |
|---|---|---|
| 13h50 | Mention indirecte | Apparition du logo et de l'écran de recherche. Pic massif de trafic. |
| 14h20 | Mention indirecte | Accent mis sur les commentaires utilisateurs. Deuxième vague de requêtes. |
| 14h50 | Présentation directe | Consolidation de l'engagement. |
L'effet M6 en chiffres
Acquisition d'utilisateurs
La curiosité des téléspectateurs s'est concrétisée par une hausse notable des inscriptions.
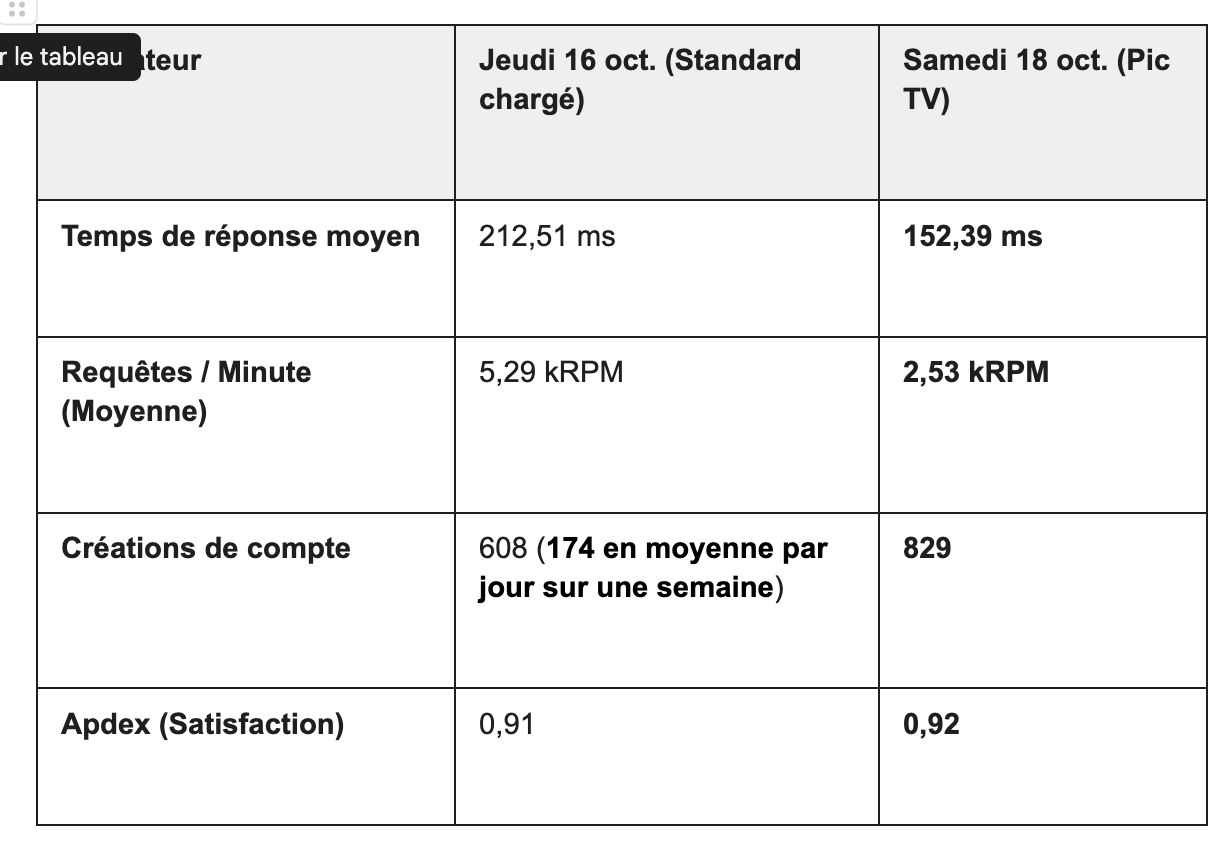
Nous avons enregistré 829 nouveaux comptes sur la journée contre une moyenne habituelle de 174 nouveaux comptes par jour.
Le plus important : aucune latence n’a été observée pendant le processus d’inscription.
Trafic web & transactions
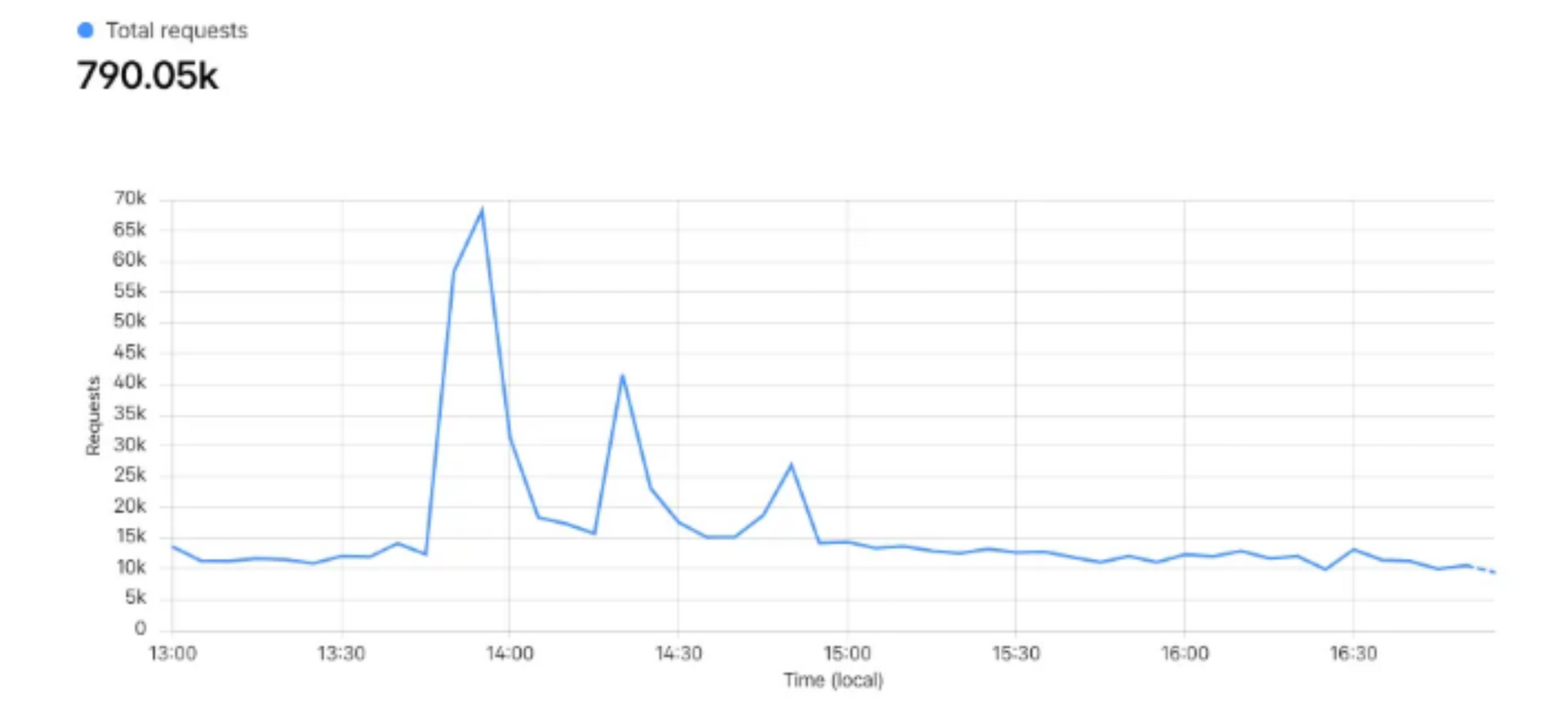
Le pic le plus impressionnant a eu lieu à 13h55 juste après la première apparition télévisée, avec 70 000 requêtes enregistrées en seulement 5 minutes via Cloudflare.
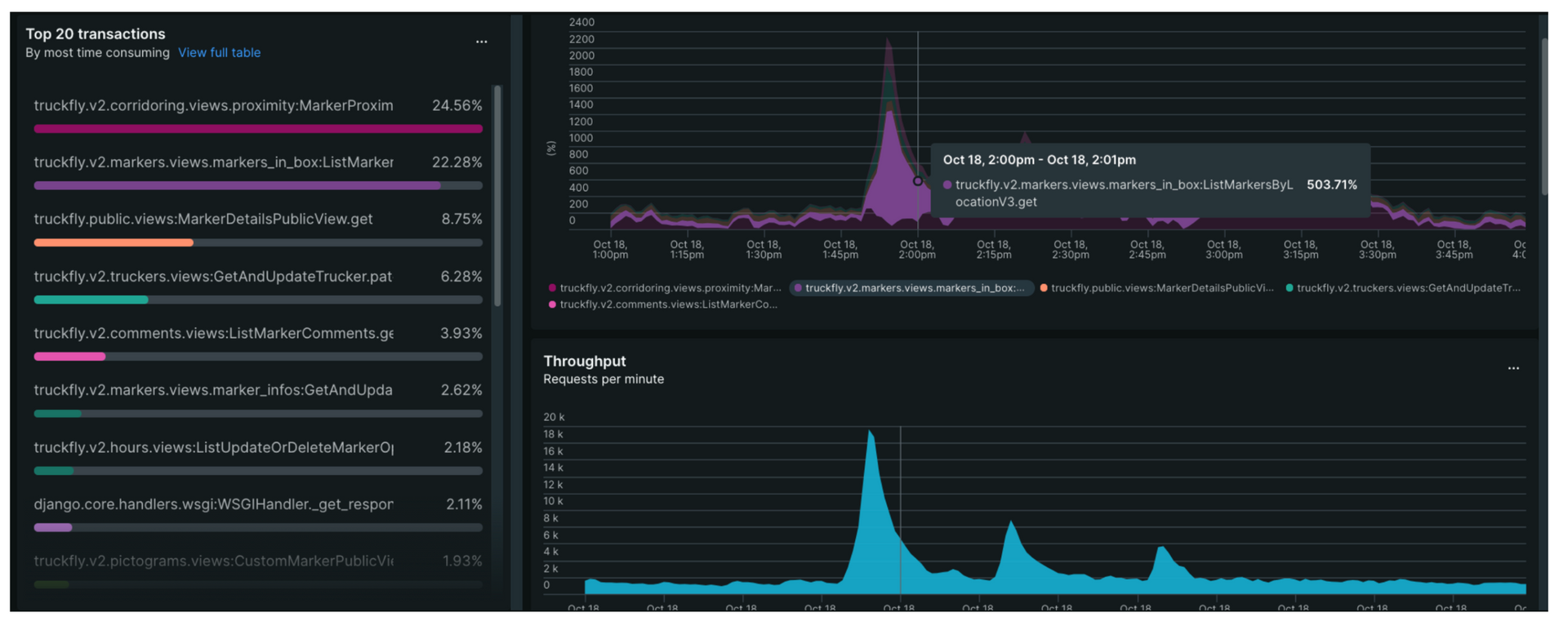
La transaction la plus sollicitée était « List Marker In Windows », utilisée pour afficher les points d’intérêt sur la carte.
Cette requête étant exécutée dès l’ouverture de l’application, elle constituait le premier véritable test de résistance de notre backend.
Pendant l’émission, nous sommes passés d’environ 2 000 à 20 000 requêtes par minute en moins de 5 minutes.
Lors de tests réalisés auparavant sur l’infrastructure standard, le système devenait rapidement lent jusqu’à devenir indisponible. Cela confirmait qu’il était impossible de conserver l’architecture habituelle pour ce type d’événement.
Comprendre le problème
Pourquoi un pic lié aux diffusions M6 est-il particulièrement difficile à gérer ?
Le principal problème avec un passage sur M6 et TF1 est son imprévisibilité.
Nous ne savons jamais réellement à quoi nous attendre : tout dépend du public de l’émission, de la manière dont l’application est présentée et de l’intérêt qu’elle suscite chez les spectateurs.
Il faut donc estimer la charge potentielle à partir de probabilités basées sur l’audience moyenne de l’émission et le public cible.
Trafic soudain vs montée progressive
La différence entre un trafic soudain (spike) et une montée progressive (ramp-up) réside principalement dans la capacité du système à s’adapter en temps réel.
On peut comparer cela au remplissage d’un verre d’eau :
- dans un cas, on remplit doucement le verre au robinet ;
- dans l’autre, on jette directement un seau d’eau dessus.
Dans une montée progressive, l’infrastructure a le temps de créer de nouvelles instances et de répartir correctement la charge.
Dans un spike brutal, tout arrive d’un coup et le système peut rapidement saturer avant même d’avoir eu le temps de réagir.
Les symptômes d’une infrastructure qui ne tient pas
Lorsqu’une infrastructure commence à flancher sous le poids du trafic, elle ne s’arrête pas forcément immédiatement.
Elle passe généralement par une phase de dégradation progressive :
- augmentation de la latence ;
- ralentissements ;
- saturation CPU/mémoire ;
- erreurs applicatives ;
- puis crash complet et indisponibilité.
La préparation
L’infrastructure de l’application est hébergée sur Microsoft Azure.
Nous utilisons :
- Azure App Service pour le backend Django/Python ;
- Azure Front Door pour la distribution du trafic ;
- PostgreSQL Flexible Server pour la base de données.
Notre objectif était simple : absorber le pic de charge sans interruption de service.
Pour cela, nous avons décidé de combiner deux approches :
- augmenter la puissance des serveurs (scale up) ;
- augmenter le nombre d’instances (scale out).
Comment avons-nous estimé la charge ?
Nous avons estimé la charge potentielle à partir de plusieurs éléments :
- l’audience moyenne de l’émission ;
- notre public cible ;
- les précédentes expériences similaires.
Même si l’émission a attiré des utilisateurs en dehors de notre cible habituelle, cela nous a permis d’obtenir un ordre de grandeur crédible.
Le Scale Up

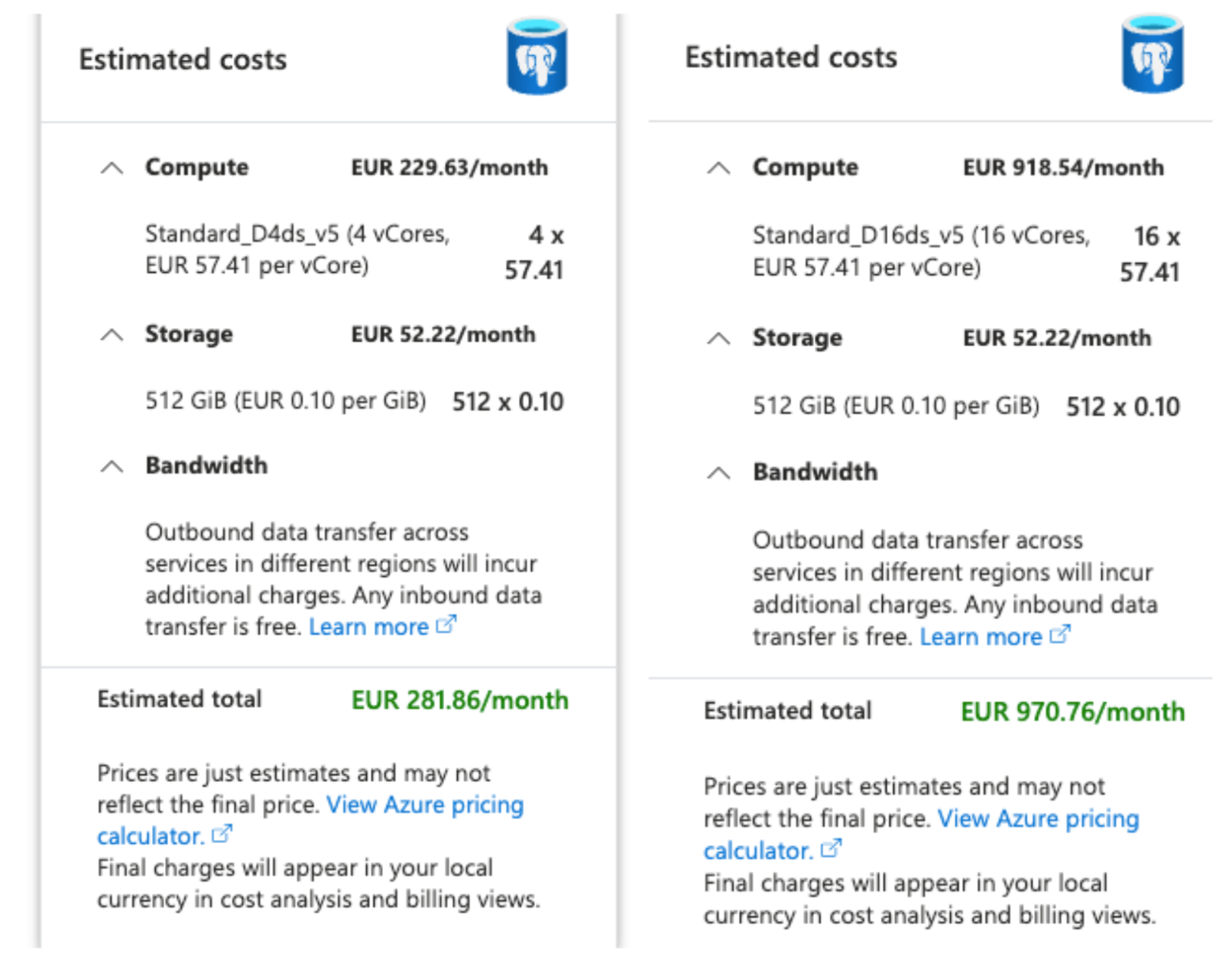
En fonctionnement standard, l’application tourne sur un App Service Plan Premium v3 P1V3.
Pour l’événement, nous avons choisi de passer sur l’offre Premium v3 P3V3 afin de quadrupler les ressources CPU et mémoire.
Nous avons appliqué la même logique sur la base PostgreSQL afin d’éviter tout goulot d’étranglement côté base de données.
Même si cette approche augmentait temporairement les coûts, nous avons préféré garantir une expérience utilisateur fluide.
Pourquoi ne pas faire uniquement du scale out ?
Nous étions limités à 30 instances maximum sur notre App Service Plan.
D’après nos estimations, ce plafond ne serait probablement pas suffisant pour absorber le pic.
Le scale up nous permettait donc d’augmenter considérablement la puissance de chaque instance.
Le Scale Out
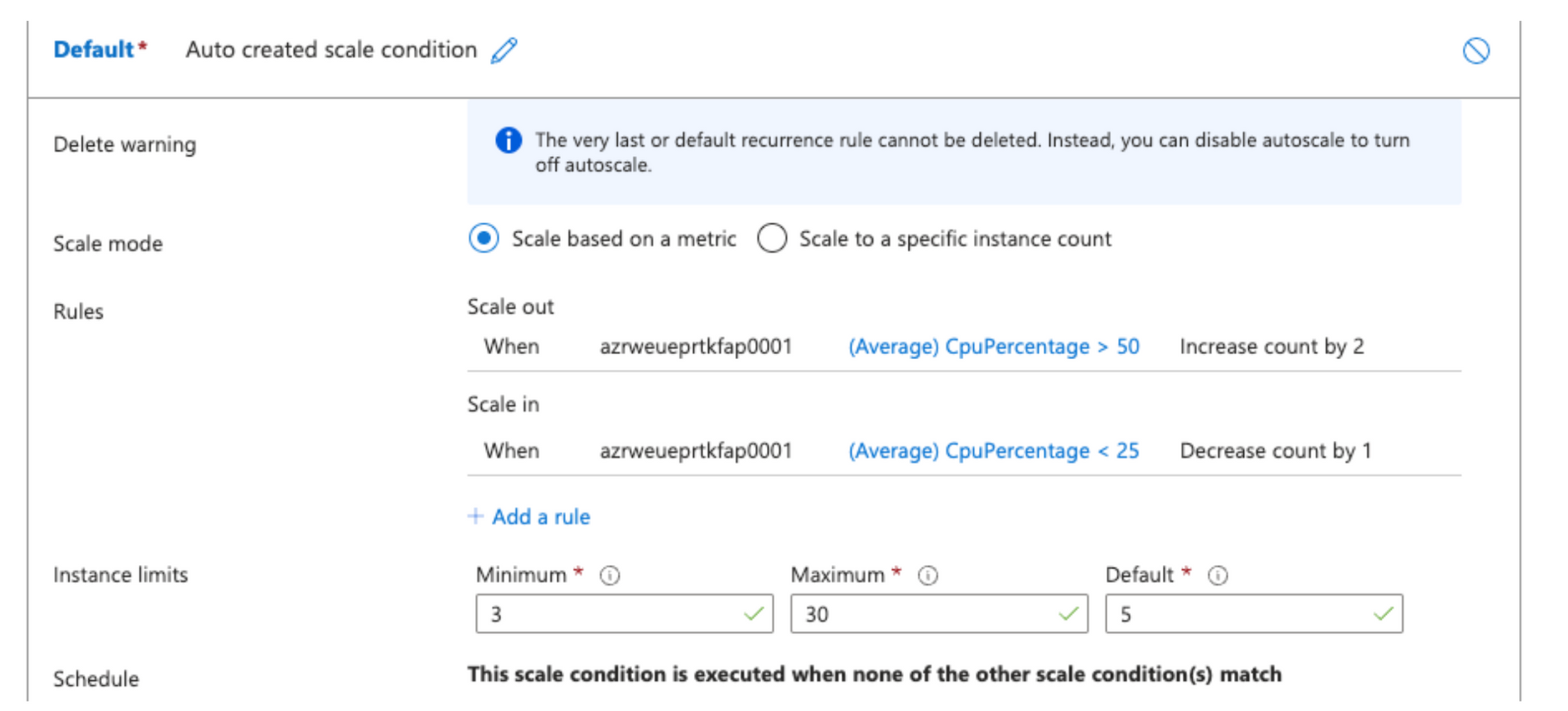
Par défaut, notre App Service fonctionne avec 5 instances et un maximum de 30.
Pour le jour de la diffusion sur M6 et TF1, nous avons augmenté le seuil minimum à 20 instances afin de disposer immédiatement d’une marge de sécurité.
Nous aurions également pu aller plus loin en ajoutant :
- un réplica PostgreSQL ;
- un second App Service Plan ;
- du load balancing supplémentaire via Azure Front Door.
Mais nous avons estimé que la combinaison scale up + scale out serait suffisante.
Avantages et limites du scale out
Le principal avantage du scale out est sa rapidité.
Les nouvelles instances peuvent être créées à chaud sans interruption de service.
À l’inverse, le scale up est généralement plus long et peut nécessiter une interruption temporaire.
Le scale out reste donc l’approche standard pour absorber des montées de charge rapides.
Performance Backend : un surdimensionnement payant
Analyse des résultats
Les résultats ont largement validé notre stratégie.
Malgré le pic massif de trafic :
- les temps de réponse sont restés stables ;
- la charge CPU et mémoire est restée sous contrôle ;
- aucun timeout critique n’a été observé.
Impact côté utilisateur
Côté utilisateur final, cela s’est traduit par :
- une navigation fluide ;
- des recherches rapides ;
- une carte réactive ;
- une application stable malgré l’afflux massif.
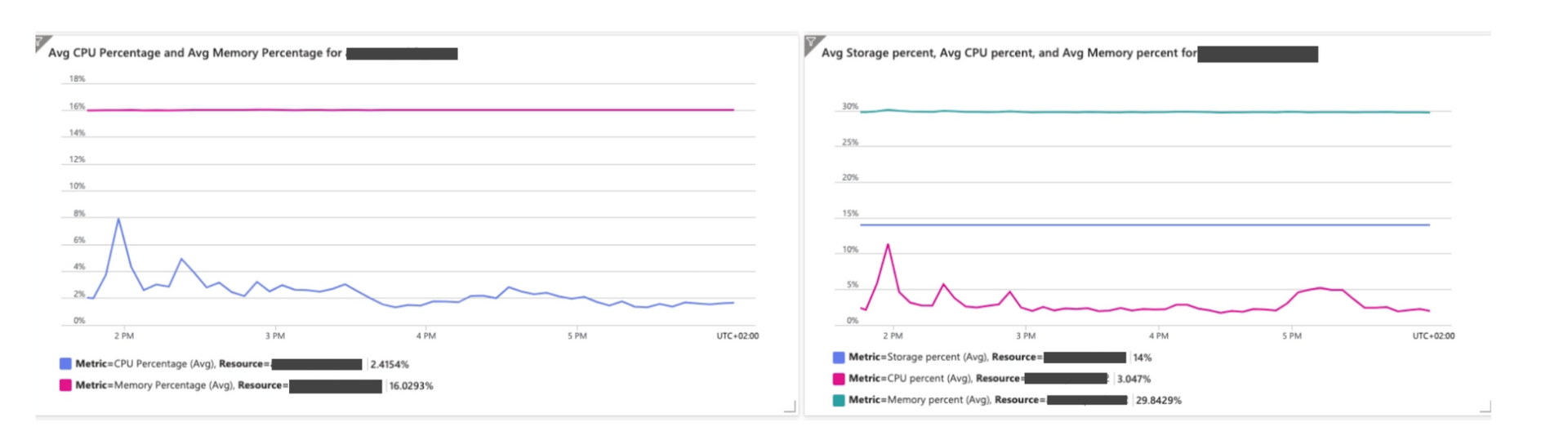
Ci-dessous on observe l'utilisation du CPU pour l’App Service Plan et la base de données, on peut noter que nous avons largement absorbé le pic de charge de l’émission :
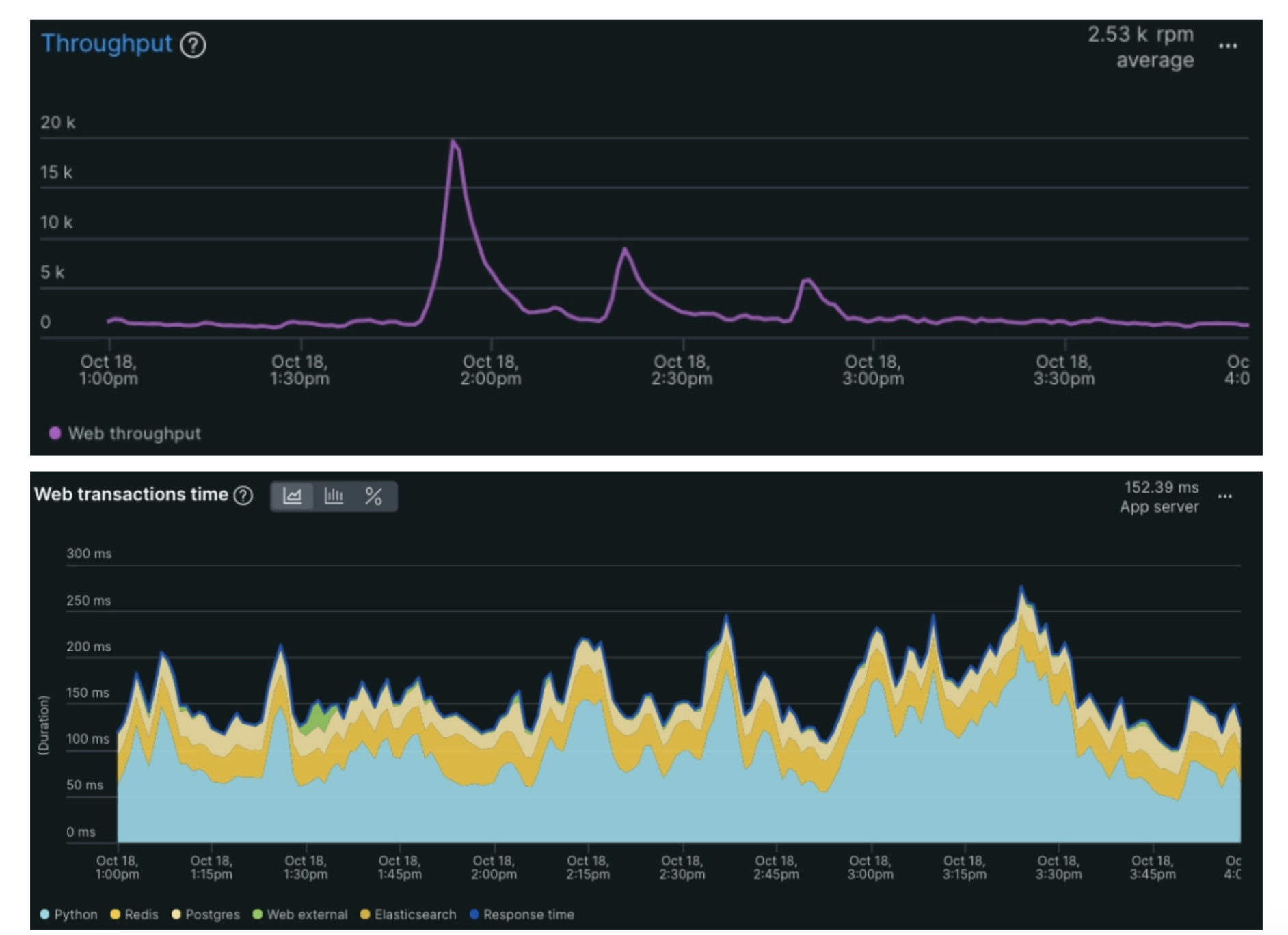
Ci-dessous le graphique des requêtes par minute, associé aux graphiques du temps de réponse pour la même période, on remarque que le temps de réponse du backend reste stable malgré le pic de charge de 20 000 requêtes par minute..
Le bilan : une opération blanche… mais sereine
Nous avions déjà vécu une expérience similaire par le passé.
Lors d’une précédente diffusion sur M6 et TF1, nous avions principalement misé sur le scale out.
L’application avait tenu jusqu’à atteindre la limite des 30 instances avant de devenir indisponible pendant plusieurs minutes.
Cette expérience nous a appris une chose essentielle : mieux vaut être trop prudent que pas assez.
Le coût supplémentaire de cette opération s’est élevé à environ 325 €.
Au regard du risque d’indisponibilité, du potentiel d’acquisition utilisateur et de l’image de marque préservée, ce coût était largement acceptable.
Les principales leçons retenues
1. Prévoir large
Dans ce type d’événement, sous-dimensionner l’infrastructure peut rapidement devenir catastrophique.
2. Réaliser des tests de charge réalistes
Les simulations permettent d’identifier les limites réelles de l’infrastructure avant le jour J.
3. Anticiper en amont
Éviter les déploiements applicatifs juste avant l’événement et préparer les serveurs suffisamment tôt.
Bonnes pratiques pour gérer un pic de charge sur Azure
Étapes clés
- Étudier l’audience potentielle ;
- Réaliser des simulations de charge ;
- Préparer les règles d’autoscaling ;
- Éviter les mises en production avant l’événement ;
- Superviser l’infrastructure en temps réel.
Erreurs à éviter
- Sous-estimer la curiosité des spectateurs ;
- Ne compter que sur le scale out ;
- Préparer l’infrastructure trop tardivement ;
- Négliger le monitoring.
Outils recommandés
- Azure App Service ;
- PostgreSQL Flexible Server ;
- Azure Front Door ;
- New Relic ;
- Azure Monitor.
❓ FAQ
Comment Azure gère-t-il l’autoscaling ?
Azure permet de définir des règles de scaling basées sur différents indicateurs comme le CPU, la mémoire ou le nombre de requêtes.
Il est également possible d’utiliser des mécanismes automatiques plus avancés qui ajustent dynamiquement le nombre d’instances selon la charge réelle.
Quelle est la différence entre Azure App Service et Kubernetes ?
Azure App Service est généralement plus simple à administrer pour des applications monolithiques.
Kubernetes devient particulièrement intéressant pour les architectures microservices où chaque composant doit pouvoir scaler indépendamment.
Azure Container Apps représente aujourd’hui un excellent compromis : il repose sur les mécanismes de scaling Kubernetes tout en conservant une simplicité proche d’App Service.
Combien coûte un pic de charge sur Azure ?
Le coût dépend principalement :
- du nombre d’instances ;
- du niveau de scale up ;
- de la durée du pic ;
- des services associés.
Dans notre cas, le surcoût total de l’opération a été d’environ 325 €.
Prochaine étape
Notre prochaine évolution sera d’optimiser encore davantage les seuils d’autoscaling afin d’améliorer le ratio coût/performance lors des prochains événements.
Autre approche possible
Sur certains projets vitrines sans connexion utilisateur, il est également possible de transformer le site en contenu statique.
Les pages sont alors générées à l’avance et les serveurs n’ont plus qu’à distribuer du contenu déjà préparé.
Cette approche réduit énormément la charge backend et permet d’absorber des volumes de trafic très importants avec peu de ressources.
Ressources Agaetis




